

An out-of-the-box security scanner gets you most of the way there. It knows the common vulnerability patterns, applies standard rules, and catches a broad class of issues across any codebase. But "most of the way" isn't the same as "accurate for your codebase." Every organization has context that a generic ruleset can't account for: which directories are test-only, which frameworks handle sanitization, which services are internal. That last 20% of accuracy, the gap between a useful scanner and one your developers actually trust, requires a healthy amount of customization.
Semgrep has always been built around this idea. Custom rules let teams encode detection logic specific to their codebase. Semgrep Memories offer an alternative path: natural-language instructions that teach Semgrep what's a real vulnerability in your codebase and what's noise. When a scanner flags a SQL injection finding in a file that only runs in a test environment, a memory tells Semgrep to recognize that pattern and stop flagging it.
For the Remediation at Scale report, we analyzed thousands of memories authored by security teams on the Semgrep platform to understand what organizations are actually encoding. The patterns reveal something useful: false positives aren't random, and the knowledge required to eliminate them falls into a small number of recurring categories.
Nearly half of all memories address two sources of noise
When we clustered the full set of platform memories by goal, two categories dominated. Non-production environment memories account for 25.6% of all memories written. Framework protection memories account for 21.9%. Together, these two categories represent nearly half (47.5%) of all the context security teams are adding to their Static Application Security Testing (SAST) scanners.
Non-production environment memories tell the scanner that certain code paths, directories, or repositories never run in production. A development configuration file with a hardcoded credential isn't a secret if it's never deployed. A Terraform module that isn't applied to any environment isn't an attack surface. These memories encode that context:
"Scripts whose purpose is to set up or manage a developer's local environment are never executed in the deployed application, so security findings in those scripts can be ignored."
"Files located in the certificates/ directory are used exclusively for local development and are never deployed to production. Security findings detected under this path cannot be exploited in production and may be ignored."
Framework protection memories capture compensating controls that generic scanners can't see. Your internal @auth_required decorator enforces authentication. Your ORM's query builder prevents SQL injection. Your application routes through middleware that validates JWT tokens. Without this context, the scanner flags patterns that your framework already handles:
"All routes in this application pass through the AuthMiddleware class, which validates JWT tokens; findings flagging missing authentication are false positives."
"Any Stripe API key that begins with
sk_test_indicates a non-production test credential and is not sensitive; hard-coded occurrences of those test keys can be ignored."
These two categories alone represent the most common source of repetitive false positives. If you're just getting started with memories, this is where to focus.
What security teams are teaching their scanners
Beyond the top two categories, the full distribution of memory themes reveals that teams are encoding nine other distinct types of institutional knowledge. Here's the complete breakdown from our analysis:
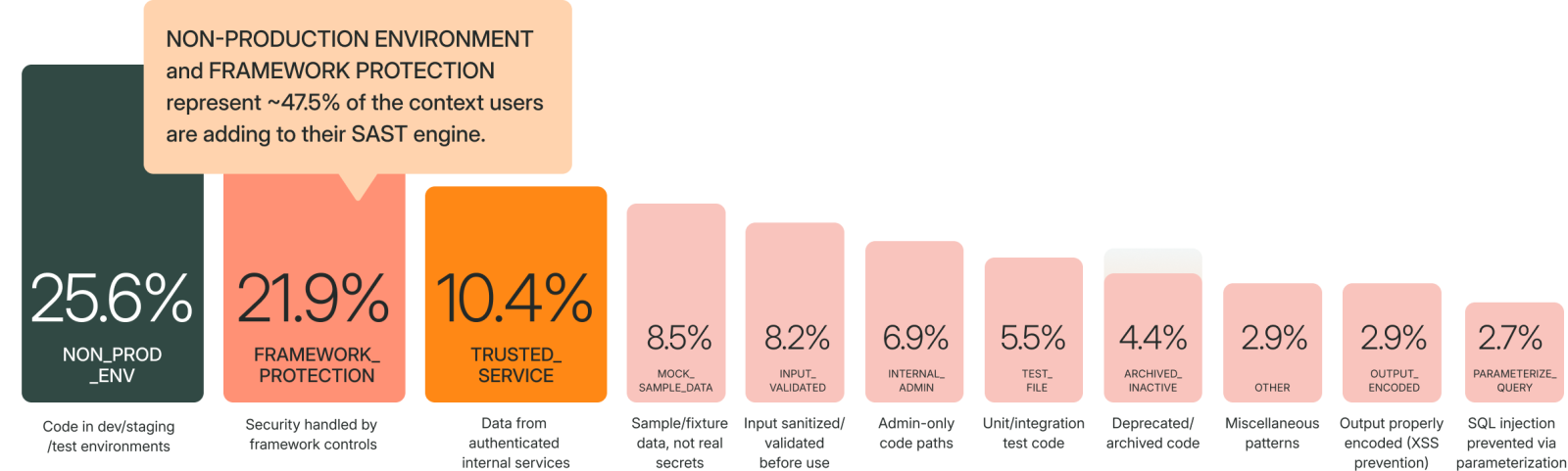 Trusted service context (10.4%) tells the scanner when data originates from a controlled internal source. If a deserialization call processes data from an internal preprocessing service rather than user input, the risk profile changes. Teams write memories like: "Findings involving URLs obtained via
Trusted service context (10.4%) tells the scanner when data originates from a controlled internal source. If a deserialization call processes data from an internal preprocessing service rather than user input, the risk profile changes. Teams write memories like: "Findings involving URLs obtained via getResource() should be ignored because these methods only access local resources, not external HTTP requests."
Mock and sample data (8.5%) addresses findings in example code, fixture data, and vendored third-party libraries. A hardcoded credential in a test fixture isn't a production secret. A vulnerability in vendored sample code from an SDK isn't your attack surface.
Input validation acknowledgment (8.2%) captures cases where input is validated through mechanisms the scanner doesn't track. A public Firebase API key starting with 'pk.' is designed to be client-facing. An f-string passed to a SQL query is safe when every interpolated variable is strictly typed as numeric.
Internal/admin-only paths (6.9%), test files (5.5%), archived code (4.4%), output encoding (2.9%), and parameterized queries (2.7%) round out the taxonomy. Each represents a specific type of context that, without a memory, would require a human to re-evaluate every time the same pattern appears.
The common thread: none of these are exotic edge cases. They are the same decisions security teams make repeatedly during triage. Memories encode those decisions once so the AI can apply them at scale.
Two paths to the same knowledge base
There's an old saying in engineering: never spend 10 minutes doing something by hand when you could spend 30 minutes automating it. The math actually works out in your favor... eventually. Memories follow the same logic. Writing one takes a few minutes. The triage time it saves compounds across every future scan.
Memories reach the platform through two mechanisms, and understanding both is important for getting the most value from the feature.
Authored memories are written proactively by security teams. An AppSec engineer who knows that a specific directory contains only development tooling can write a memory that covers every finding in that path. This is the fastest way to eliminate an entire class of false positives at once. Think of it as writing a triage policy rather than triaging individual findings.
Auto-suggested memories are generated when someone triages a finding. When a developer dismisses a finding during a pull request review and provides context for why, Semgrep Multimodal can convert that triage decision into a suggested memory for admin approval. This turns routine triage into a feedback loop: individual decisions become institutional knowledge.
Both paths feed the same system. Whether a memory is authored top-down by a security team or suggested bottom-up from developer triage, Semgrep applies it across all future scans.
Where to start
If you're looking to reduce repetitive false positives in your SAST program, the data points to a clear starting sequence.
Start with non-production environments. Identify directories, repositories, or file paths that never run in production: local development scripts, CI/CD configuration utilities, Terraform modules for decommissioned infrastructure. Write one memory per pattern. This single category accounts for more than a quarter of all memories on the platform, which suggests it's also the largest source of repetitive noise.
Then encode your framework protections. Document the security controls your frameworks and middleware already enforce: authentication decorators, ORM-based query builders, output encoding utilities, CSRF middleware. These are the patterns that generate the most frustrating false positives because the developer knows the finding is wrong but the scanner can't see the compensating control.
For detailed guidance on writing effective memories, the best practices documentation covers structure, scope, and common pitfalls.
The full analysis of memory patterns, alongside data on remediation rates, time-to-fix distributions, and feature effectiveness across hundreds of organizations, is available in the Remediation at Scale report. It includes fix rate analysis by OWASP category, ecosystem-specific SCA data, and a prioritized set of recommendations organized by implementation timeline.

.jpg)